导言
最近在学习一些基于激光雷达数据的3D目标识别算法,于是就写一些学习笔记希望能帮助到同样有兴趣的各位。
3DSSD是发布在2020 CVPR上的作品,采用了基于点云的预测方法,使用原始点云数据进行特征提取并做proposal。对于类似的方法,模型的结构往往借鉴PointNet++的框架:点云数据->骨干网络特征提取->上采样插值->检测头输出预测。3DSSD为了取消费时的上采样插值部分,提出了新的F-FPS和Fusion Sampling作为补偿。
在PointNet++的特征提取模块中,数据经历了三个步骤:
- 点采样 (Point Sampling)
- 因为点云数据过多,需要使用 Furthest Point Samping (FPS)对所有点进行下采样
- 分组 (Point Grouping)
- 将采样过后得到的点作为中心点,以这些点为中心,将采样前所有特征点使用KNN或者Ball Query的方法分配到各个中心点所处的空间内
- 特征聚合 (Feature Aggregation)
- 将每一个空间点内的特征点的特征以一定方式聚合到中心点上,这样中心点就包含了组内所有点的特征。
主要改进
F-FPS 采样方法
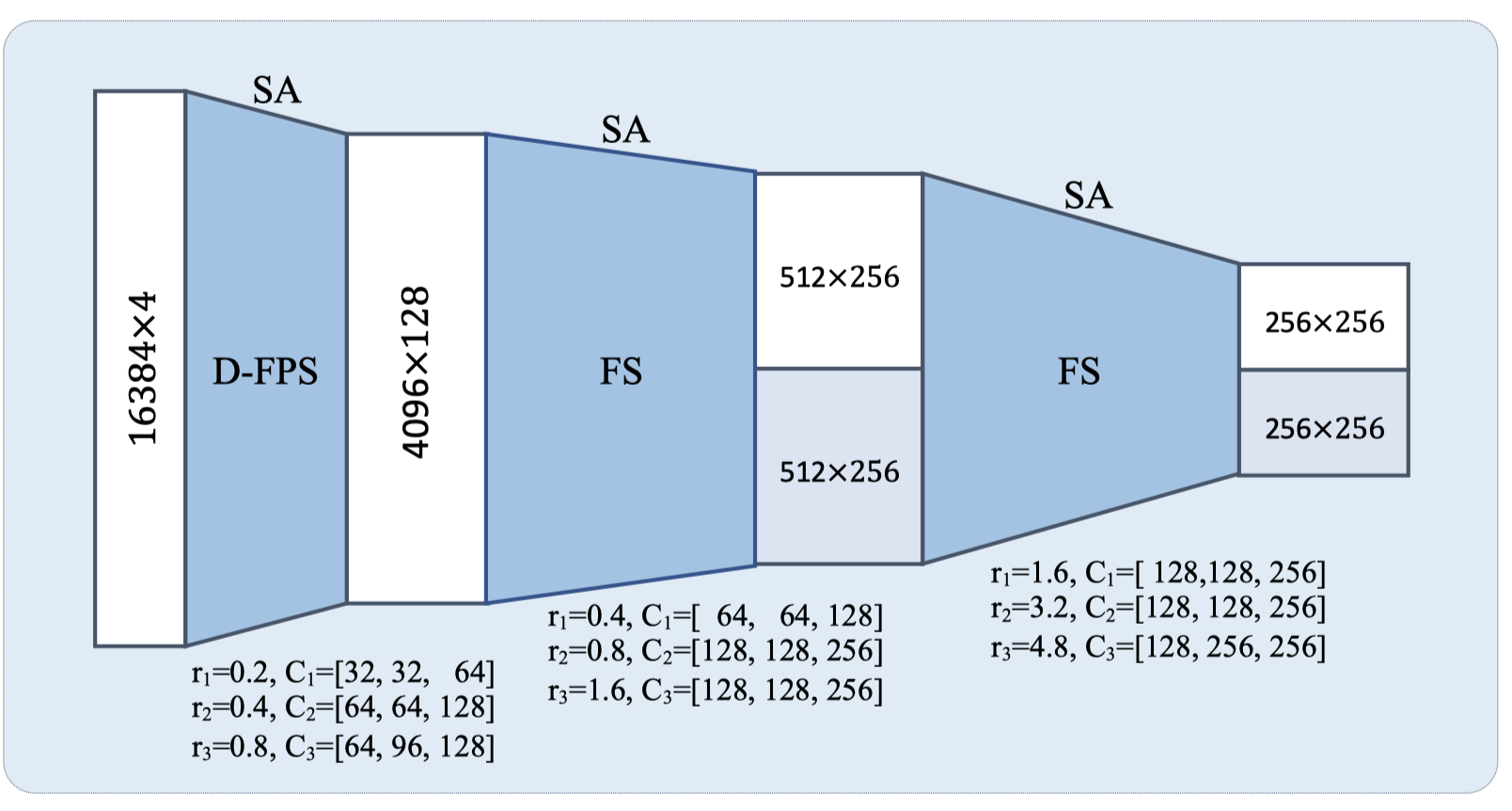
在骨干网络提取特征时,随着网络加深需要使用FPS方法下采样坐标点,常规的做法是根据点的空间坐标来下采样(distance-FPS),即假设采样空间坐标差异大的点有助于保留整体点云的信息,本论文中提出了feature-FPS的方法,使用每一层获得的点的特征来下采样,即假设保留特征差异大的点有助于体现整体点云信息。
 |
|---|
| 骨干网络示意图 |
实验证明feature-FPS有助于保留前景点,提高采样的recall(即能采样到更多在目标内的点)。但是仅使用feature-FPS会造成很多点被认作false positve而导致objectness分类准确率降低(我的理解是会造成样本数量不平衡),因此文章又提出了Fusion Sampling的策略,即每次采样时用feature-FPS采样一定数量的点,另外的点用distance-FPS采样。
需要注意的是,在连续两个采用 Fusion Sampling 策略的特征提取模块堆叠时,第二个feature-FPS只会从之前feature-FPS获得的点中采样,对distance-FPS也是如此(如上图)。
Anchor-free 检测头
网络为了更加轻量化,使用了anchor-free的预测生成策略,对于每一个seed点(voting之后的特征和坐标),直接对其回归一个表征预测框的向量 ,包含了该点对真实目标框中心的位移,长宽高的偏移,角度的bin类别和相对该bin的位移(角度被分为12个bin,每个bin为30度)。
除此之外当然还会对目标的类别进行预测,区别是在生成类别真实值的标签时,我们不仅会对点所属的类进行监督(即在一个one-hot类别向量上哪一个维度非零),还会对点靠近中心的程度进行监督,即在点所属的类别的维度上用以下结果代替1:
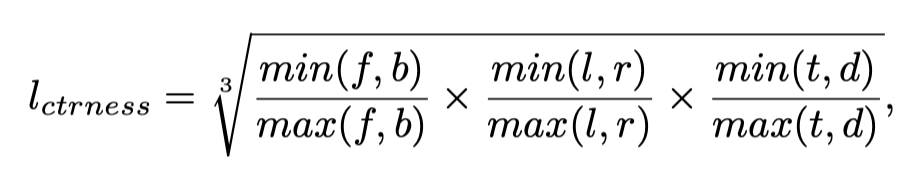 |
|---|
| centerness标签计算 |
在计算loss时,我们使用huber loss(smoothL1)计算各个偏移量的loss;paper中写到对点的类别使用了cross entropy,在实现中其实是一个binary cross entropy:
cls_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=gt_cls, logits=pred_cls)
代码实现
官方代码使用tensorflow实现,应该是参考了PointNet++的实现:官方TF1实现
还有一个用pytorch的复现,小心使用,很多问题,我在自己fork的repo修复了一部分,目前还没完成:pytorch复现
mmdetection3d有一个成功的复现:mmdetection3d框架
建议阅读
对于骨干网络的其他部分,尤其是对vote机制,可以参照VoteNet的实现,几乎一样。