导言
多模态3D目标识别任务常常要融合Image相片信息和Lidar点云数据,以此来为单纯依赖点云的方法添加相片中的材质纹理和颜色特征。imVoteNet是今年CVPR2020上发布的论文,主要思想在于使用成熟的2D目标检测器辅助3D检测器propose检测框,以此来缩小3D检测器的搜索范围。
我觉得可以借鉴的点有:
- 网络结构:采用了独立的2D检测器生成2D预测结果,预测结果通过某种方式反馈到3D点云中去,总体上看起来是late fusion的模式。可以使用任何2D检测器和类似VoteNet的点云3D目标检测模型,甚至可以使用在体素方法上(在相机视角上压缩)。
- 训练方式: 使用了Multi-tower training来调节不同来源的特征的收敛速度。
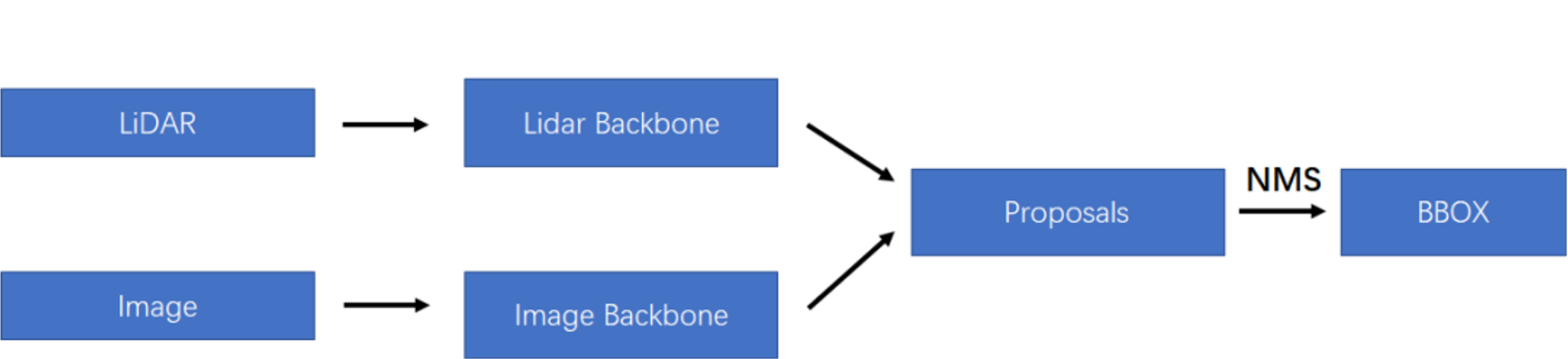 |
|---|
| Late Fusion |
主要方法
2D特征提取
2D特征提取主要依赖于一个训练完成的检测器,大概流程如下:
- 2D检测器检测图片, 输出目标框和目标类别。
- 将3D目标检测器输出的seed point,也就是下采样得到的可能存在目标的点投影回图片中。
- 如果投影回图片中的点恰好落在2D目标框内,则对该点对应的像素提取三种特征:
- geometry特征:通过该像素相对2D目标框中心的位移(2D Hough Vote),估计出的伪3D Hough Vote。
- semantic特征:可以是对应2D目标框抽取出的特征向量,也可以直接是分类结果的one-hot向量。
- texture特征:可以是投影像素领域上的RGB值,也可以是单像素的RGB值。
semantic和texture特征都比较容易理解,提取geometry特征的示意图如下:
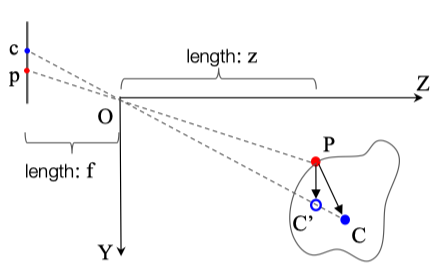 |
|---|
| geometry特征 |
Geometry特征即为由向量估计出的3D向量(理想情况下我们希望估计出,但是倘若物体距离镜头很远的话,和在z轴上的差距可以忽略不计)。同时为了一定程度上弥补这种估计带来的不准确性,geometry还包括了向量的方向。因此对于点P我们有geometry特征:
Multi-tower training
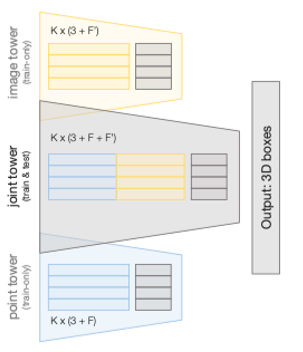 |
|---|
| Multi-tower Head |
为了解决不同来源的feature在问题优化中步调不一致的问题,文章采用了multi-tower的方法对模型进行训练。也就是同时使用2D特征、3D特征以及2D和3D特征联结分别训练一个VoteNet检测头(先vote,再propose)。
这样一来训练的loss就为三个检测头的loss的加权平均,文章也试验了不同的权重组合,最终得出2D:3D:(2D+3D)=0.3:0.3:0.4时效果最好。
虽然在训练时使用三个独立检测头,但实际模型推理仅仅使用(2D+3D)这一个检测头来预测结果。
建议阅读
现在源码已经放出,可以试着阅读:
imvotenet源码
同时,mmdetection3D框架上有老哥放出了不带Multi-tower的pull request:
mmdetection3d的imvotenet pull request