导言
Generalized Focal Loss (GFL) 是一种通过调整框本身和框质量(好坏)估计的表示,来提高模型学习效果的技术。最近这个方法也推出了v2的版本,这种思路总体上会比较轻量,不会给模型本身带来很多的overhead,非常不错。
Motivation
GFL要解决的问题主要有两个:
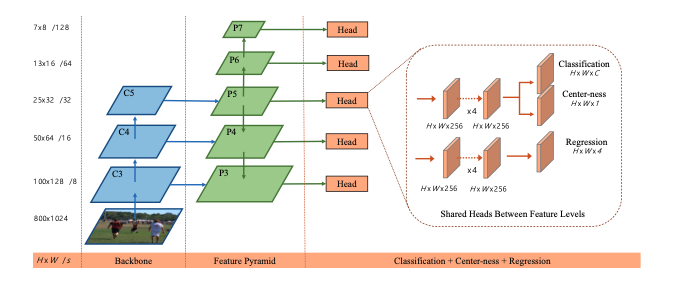
- 分类分支和框质量分支在训练时不一致,在测试时却需要共同决定框表示。对于先前的很多anchor-free检测器来说,除了对特征图中每个像素对应的检测框回归外,还需要用一个额外分支回归框的质量(centerness或者gIOU),最后使用NMS参考这个质量值去掉那些不好的检测框(偏离中心的框)。这个分支在训练时是单独训练的,如下图FOS的模型结构中最右侧的center-ness分支,在预测时却是和分类分支得到的信度相乘得到最终预测框的信度。
- 传统的框表示太过于strict,可能对于模棱两可的边界不够友好。先前的方法都对像素点到边界的距离回归,这些距离都是hard-coded的,不存在随机性;从概率的角度说就是这些回归对象满足狄拉克分布(只在hard-coded的完全正确值上有概率)。
解决方法
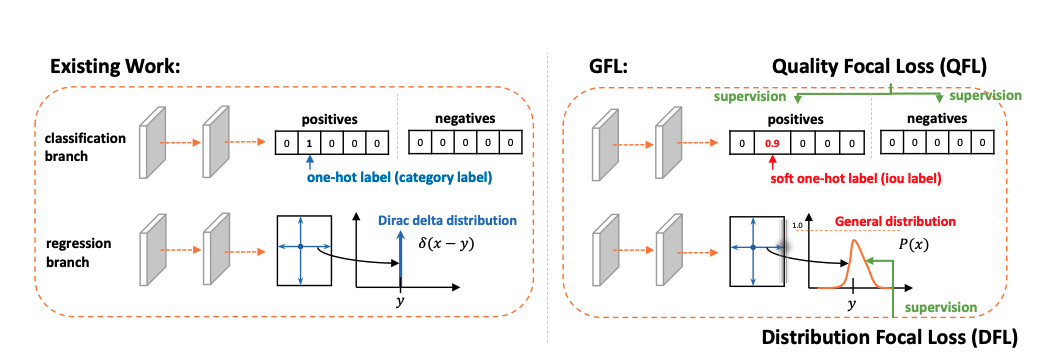
解决问题1:
为了让分类分支和框质量分支在训练测试时一致,所以文章就想办法整合他们一起训练。具体的方法是在搭label的时候使用框质量作为正确类别one-hot encoding上的值。此时这个值位0~1之间的浮点数,如此一来传统的focal loss也不能使用了,于是改为这个叫Quality Focal Loss的这个损失函数:
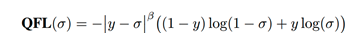
为框质量的目标值,为正确类别的框质量预测值。
解决问题2:
既然框的表示使用狄拉克分布太strict,于是作者就尝试用一个general的分布来对框表示建模,即,每个距离值y都有一定的概率取到,最后像素到框四个边的距离由这个分布的积分得出。具体的,对像素到每一边的距离,最后预测的是一个n维向量(四个边就是4n维),每一个维度都代表预测值取得可行域中某一个值的概率。因为是概率分布,每个n维向量的值加和都要等于1(用softmax处理即可)。同时加入了一个新的loss函数来对学习分布进行监督,称作Ditribution Focal Loss:
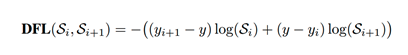
为目标值, 和为最靠近的两个边界,分别为这两个值所表示的概率。总的来说这个loss的目的是提高取得目标值的概率。
以上两个方法的通解
以上两个问题的解决方法可以写为通用的形式,也就是GFL:
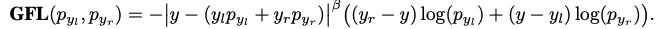
V2版本改进
实验证明学习到的框的边界分布和框的质量有很大的关系,如果一个框的边界越明确,那么对应的分布肯定很集中,这样的检测框的质量也会高一些。作者在v2版本中尝试使用框的边界分布取指导框质量的回归。
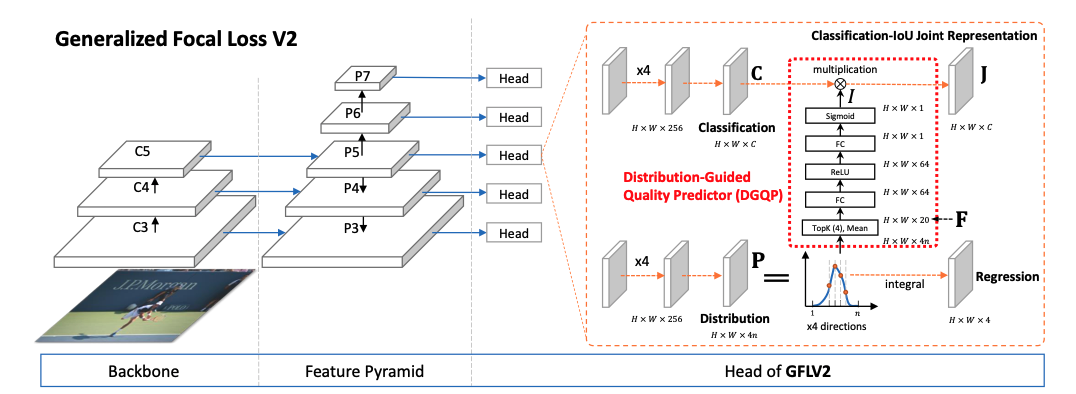
具体的做法就是在得到框的概率分布后,取得每个分布的topk概率值,一般地,topk数值的和越大,那么这个分布就越集中,所对应的预测框就越明确。最后通过一堆全连接层提取特征以后得到一个由框边界分布而来的分数,将这个分数乘到分类分数上去得到最后的信度。
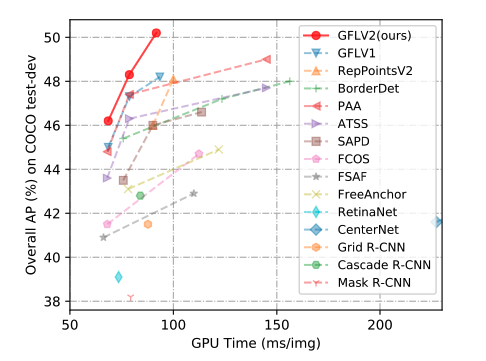
以上的改进被证明对最后的预测结果比较明显的提升:
引用
GFL version 1: paper
GFL version 2: paper
GFL code: codebase